
 ℂ Cobol
. Html
. Debug
. Note
. Db2
. Oracle
.PostgreSql
. Video
ℂ Cobol
. Html
. Debug
. Note
. Db2
. Oracle
.PostgreSql
. Video
 Javascript
. overview
. function
Javascript
. overview
. function
 Vue
. overview
Vue
. overview
 AngularJS
. overview
AngularJS
. overview
 React
. overview
. Contact us
React
. overview
. Contact us
|
Future is here
"All your dream projects can become reality", contant us
|
Perché non guardare i costi ed aumentare l’efficienza
| |
|
 |
|
|
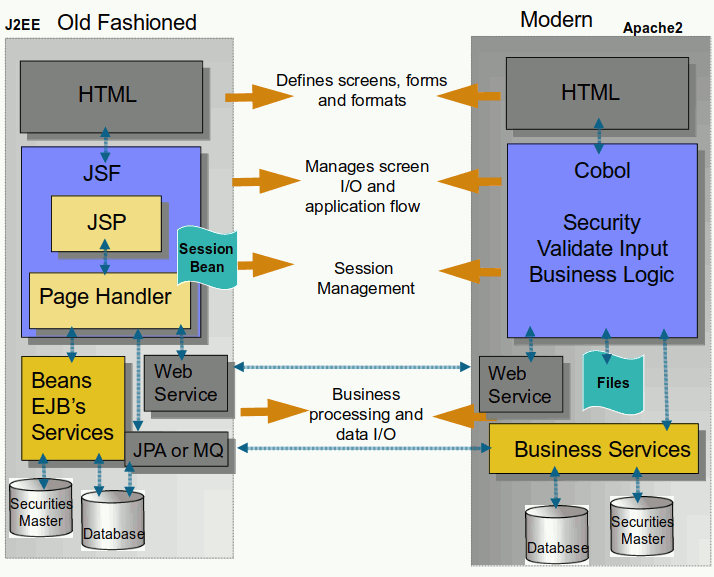
(Il Business Services e Web Service realizzati in Cobol)
| |
Tutti i prodotti realizzati con Cobol e Html sono
utilizzabili su qualsiasi elettrodomestico dotato di brouser, da
decenni funzionano su smartphone, sulla tv, sul frigorifero, senza nessun "driver",
senza gli aggiornamenti quotidiani.
I programmi ed il profilo utente controllano ogni elemento della pagina
nel senso di visibilità, modificabilità, focus eccetera. Invece
i colori i fonts la mobilità tra le pagine, sono completamente liberi.
La grafica separata della gestione,
le pagine html sono separate dai programmi, sono a se stanti,
possono essere completamente variate, punto fondamentale da rimarcare,
le pagine sono pilotate, tutto è deciso nei programmi,
la pagina chiede, il programma dispone, sono la proiezione e non vincolano la navigazione.
Mediamente nei progetti gestionali l’interfaccia utente
(UI, User Interface) non arriva alle due cifre e non deve vincolare a tortuosi
artifici di mobilità e gestione dei dati.
Avete in interfaccia a caratteri (3270)?,
per trasformarla in Html, basta un click, più
di un quarto di secolo di esperienza, tempi di riposta, manutenzione
nell’ordine di frazione nel confronto con altri linguaggi.
Confronto con altri linguaggi,
Oggi i linguaggi di moda sono OOP hanno delle significative caratteristiche,
non riducono:
(1) ne i tempi di sviluppo
(2) ne i tempi di cpu
(3) ne i tempi di manutenzione
(4) ne i tempo di ingegneria del software.
La programmazione OOP è perfetta per tematiche semplici,
scolastiche, il punto due riassume, ma, Voi, avete
mai visto un giocoliere o un lanciatore di coltelli che si trova variati i
suoi oggetti. Un esempio di OOP:
se non hai la versione 17 non parte il Developer, ne segue, punto:
(5) si è
diventati "versione dipendenti".
Riflessioni,
Sicuramente è bello avere oggetti
a fisarmonica con decine di attributi ed usarne solo alcuni, ordinati a piacere ma non
è senza controindicazioni. Cosa cambia tra una Copy ed una Classe ... tra una Call
ed un Package? Sicuramente cambia alla chiusura della Call ed aspettare il ritorno di
un messaggio, il return-code di ogni istruzione e la gestione delle eccezioni, le pagine
html gestite dal grafico e la matassa inguardabile ed ingestibile negli altri casi.
|
< |
 |
>
| |
Debug essenziale, realizzato con solo Cobol - "free".
Per le funzioni web http bisogna attivare online il punto di partenza, da un
terminale remoto si può innescare il debug, come nelle immagini sopra
riportate. Il dizionario dati, utilizzato per vedere o modificare il contenuto dei
dati è realizzato in rexx, analizzando i sorgenti le copy e le include.
In alternativa per ambiente Cics-TS si può utilizzare il debug Ibm, prodotto
completo e sofisticato, intercetta le transazioni web in debug, dando la massima
operatività ed in qualsiasi momento rilascia il controllo all’utente.
La qualità del prodotto è direttamente proporzionale alla qualità
del debug, alla modalità e tempestività d'intervento.
Comandi Attivi:
BOTTOM ⇒ si posizione in coda al listato del programma
CLEAR ⇒ cancella la "variabile + valore" messo in evidenza con MONITOR
FIND/F + "valore" ⇒ ricerca nel programma la scritta
HELP ⇒ riassume i comandi e funzioni attive
MONITOR ⇒ tiene in evidenza il contenuto della "variabile + valore",
nel caso di una struttura mostra le enne righe dei singoli campi
MOVE "valore"/variabile1 TO variabile2 ⇒ imposta il contenuto ("valore") della variabile2
TOP ⇒ si posiziona all'inizio del listato del programma
Funzioni Attive:
f1 ⇒ elenca le funzioni attive
f2 ⇒ avanza di uno step
f3 ⇒ chiude il debug
f4 + il cursore sul campo ⇒ visualizza il contenuto
f5 + scritta in "command line" ⇒ ricerca nel listing
f6 + cursore in "prefix line" ⇒ attiva il breakpoint o lo toglie se ripremuto
f7 ⇒ si sposta di una pagina all'indietro
f8 ⇒ si sposta in avanza di una pagina
f9 ⇒ avanza fino allo "stop run" o al prossimo breakpoint
f12 ⇒ retrieve dei comandi eseguiti
|
| |
La filosofia gestionale è nata in ambiente
Z/Os, pensata per essere trasportata e scalata fino ad un portatile.
Il lato utente necessita del solo browser, per i nostalgici neanderthaliani (o
per giusta causa) di una stampante.
Come ambiente di sviluppo, presentiamo la versione Linux, dove si hanno meno
vincoli e di maggiore interesse. Si consideri che in tutti i casi
l’interfaccia utente non è sviluppata in ambiente Mainframe per
motivi di semplicità e facilità dei test.
Due oggetti fondamentali per il dialogo pagina programmi sono:
(A)
il parser dei campi variabili con la pagina ed invio pagina al browser (le
pagine html sono dei file distinti dai programmi),
(B) la ricezione della pagina al programma (passaggio dalla stringa alle singole
variabili) equivalente per tutti gli ambienti.
Due semplici programmi in Cobol Linux e due funzioni del Cics-TS nel caso di Mainframe.
Cobol o "C"
Abbiamo sempre parlato di Cobol ma usando GnuCobol dovremmo parlare di
"C" (Gcc) vista la conversione automatica prima della compila.
Cobol e Java
Ovviamente i due linguaggi non sono mutuamente esclusivi, la soluzione dove il Cobol
utilizza java è la condizione ottimale, si fruttano al meglio la
potenzialità di entrambi, versione di Cobol tipo isCobol o Micro Focus danno
una ricca documentazione.
Cosa dobbiamo installare:
- un Cobol (GnuCobol o ...)
- un framework (Komodo, Ibm.Openeditor, Opencobolide, VSCodium, V.S.C. Aibber.base, ecc.)
- per il substrato base (Aibber.base per compile, gestione folder, ecc.) di
gestione servono: Regina (rexx), The (Hessling editor con xclip (X11) e
wl-clipboard (Wayland)), Perl
- un web serser http (Apache2 o ...)
- un database (Db2, Oracle, PostgreSql e ...) ovviamente se il gestionale lo richiede
| |
Post Scriptum:
Convertire un unload di tabella da Mvs (ebcdic) in (ascii);
La tabella contiene campi Binary e Comp-3, come si procede? La versione di cobol (GnuCobol 3.2)
non contempla "RECORD IS VARYING IN SIZE ..", bisogna intervenire sulla "PIC " del file di
input, il programma generalizzato di conversione diventa specifico con:
(1) correggere la "SELECT .." e "FD .." senza parametri
(2) "PIC " lunghezza + 1 del tracciato da MVS
(3) sezionamento file da MVS con "aibbercopy.pl"
(4) "INSERT" in tabella direttamente nel programma di conversione
( Unica soluzione ammessa )
Unload-file (ebcdic):
./bin/aibbercopy.pl 113 ./tabelle comu2.binary comu2.113
Utility (NTEBCDIC):
....
SELECT ARCHIN ASSIGN TO EXT-I-FILES
FILE STATUS IS FILE-STAT.
....
FD ARCHIN.
01 REC-ARCHIN PIC X(114).
....
Structure of the table:
regina ./bin/ll_db21.rexx 2 ./source/include/RSCO2DCL.sqb ./str/comu2.str
Input parameters (NTEBCDIC.src):
....
-157- file
CODE=E037-UTF8
LRECL=113
FILE-INPUT=/home/luc/d/cobol/tabelle/comu2.113
FILE-OUTPUT=/home/luc/d/cobol/tabelle/comu2.ascii
FILE-STRUCTURE=(A),00,00,/home/luc/d/cobol/str/comu2.str
....
Run:
./loadlib/NTEBCDIC A ./bin/NTEBCDIC.src
Utility (aibbercopy.pl):
#!/usr/bin/perl -w
# ----------------------------------------------------- #
# - Split file (Aibber) - #
# ----------------------------------------------------- #
# - - - -
# example:
# perl ./aibbercopy.pl 143 ./temp cl040.txt cl040.sql
# parms: length folder file-binary "file-binary + \n"
# - - - -
# $Args = $#ARGV + 1;
$lrecl =$ARGV[0];
$dirmain=$ARGV[1];
$filein =$ARGV[2];
$fileout=$ARGV[3];
my($buf)="";
# - - Open
$filename = "$dirmain/$filein";
open(FILEIN, "<$filename")
or die goto FINE_MAIN_ERROR;
open(FILEOUT, ">$dirmain/$fileout")
or die "can't redirect FILEOUT";
select(FILEOUT); $| = 1; # make unbuffered
#
#-----Loop (1) Lettura per Split--------------#
#
$loop = 1;
$linee = 0;
while ($loop > 0) {
$bytes = read( FILEIN, $buf, $lrecl);
if ( $bytes < 1) {
$loop -= 1;
} else {
#---scrive il file di output---------------#
print FILEOUT "$buf\n";
$linee += 1;
} #--- end else
}; #--- end while (loop)
# - - Loop (1) Fine
# - - Close files
close(FILEIN);
close(FILEOUT);
$word = sprintf "%d", $linee;
$line_out = "Ok file::$filename Linee=$word";
goto FINE_MAIN;
FINE_MAIN_ERROR:
$line_out = "Ko file::$filename -- $! -- $0 (Errore +100)";
FINE_MAIN:
# print { $OK ? STDOUT : STDERR } "$line_out\n";
print STDOUT "$line_out\n";
# undef @riga;
exit 0;
# ---------------------------------------------------------- #
# http://www.tutorialspoint.com/perl/perl_read.htm
# http://perldoc.perl.org/index-overview.html
# ---------------------------------------------------------- #
|
|
| |
Install Db2-10.1 express-c su Client Linux (Ubuntu ram 32G)
Usato in modalità integrato nei programmi ( embedded database ),
il setup del database e delle tre user è abbastanza intuitivo, all’inizio il
problema della "share memery" mi ha fatto pensare di cestinare questo D.B., ma come sovente
succede è una banalità. Il D.B. si riscatta con una messaggistica
eccellente, nelle anomalie fatte durante lo sviluppo dai programmi Cobol. Dal Manzoni
"L’uom che nacque e visse senza pecca", il Bind dei programmi è un ostacolo
gratis, inutili e senza senso durante l’esecuzione dei programmi, con
errore -805 e/o -818, costringendo a tortuose manovre per i debugs.
Attenzione: i formati binary non funzionano, da Cobol a Database.
Librerie richieste:
sudo apt-get install libpam0g:i386 libaio1
sudo apt-get install ksh
sudo apt-get install lib32stdc++6
sudo apt-get install libpam0g:i386
sudo apt-get install libstdc++6
--sudo apt-get install libaio-dev
--sudo apt-get install gcc-4.9
controlla e abilita il link, per esempio:
sudo find / -name "libpam.so*"
sudo ln -s /usr/lib/i386-linux-gnu/libpam.so.0 /lib/libpan.so
./db2prereqcheck
se tutto okay, con utenza di root:
(selezionare solo lingua inglese altrimenti serve il cd)
./db2setup -l /tmp/db2setup.log -t /tmp/db2setup.trc
aggiornare .profile della user di lavoro:
# set PATH db2 bin if it exists
if [ -d "/home/db2inst1/sqllib/bin" ] ; then
PATH="$PATH:/home/db2inst1/sqllib/bin"
fi
if [ -d "/opt/ibm/db2/V10.1/bin" ] ; then
PATH="$PATH:/opt/ibm/db2/V10.1/bin"
fi
# lines have been added by IBM DB2 instance utilities.
if [ -f /home/luc/sqllib/db2profile ]; then
. /home/luc/sqllib/db2profile
fi
##LD_LIBRARY_PATH=/home/db2inst1/sqllib/lib64:/usr/local/lib/
LD_LIBRARY_PATH=/home/db2inst1/sqllib/lib64
export LD_LIBRARY_PATH
aggiornare /etc/profile:
DB2DIR=/opt/ibm/db2/V10.1
export DB2DIR
LD_LIBRARY_PATH="/home/db2inst1/sqllib/lib64"
export LD_LIBRARY_PATH
DB2INCLUDE=/home/luc/d/cobol/source/include
export DB2INCLUDE
aggiornare /etc/passwd per le tre user con la bash,
per errore di share memory:
sudo /opt/ibm/db2/V10.1/instance/db2idrop db2inst1
sudo /opt/ibm/db2/V10.1/instance/db2icrt -u db2fenc1 db2inst1
accedere e create il vostro dbpreferito:
su - db2inst1
db2start
db2 create database dbpreferito automatic storage yes
db2 get db cfg for dbpreferito
db2 update dbm cfg using SVCENAME 50000
db2set db2comm=tcpip
db2
connect to dbpreferito
GRANT DBADM ON DATABASE TO user your_user
GRANT ACCESSCTRL, BINDADD, CONNECT, CREATETAB, CREATE_
EXTERNAL_ROUTINE, CREATE_NOT_FENCED_ROUTINE, DATAACCESS,
DATAACCESS, EXPLAIN, IMPLICIT_SCHEMA, LOAD, QUIESCE_CONNECT,
SECADM, SQLADM, WLMADM ON DATABASE TO user your_user
QUIT
La configurazione base è completata, controlliamo:
su - db2inst1
db2level
db2ls
db2licm -l
db2set -all
Command line: clpplus
Suggerimento per il debug:
cmp -b -l (program).bnd (program-debug).bnd ⇒ (Δ2) (Δ1)
se (Δ1) unica presenza in (program-debug).so lanciare:
perl -i -pe 's{Δ1}{Δ2}g' (program-debug).so
|
|
| |
Install Oracle-xe-21c su Client Linux (Ubuntu ran 32G)
Usato in modalità integrato nei programmi ( embedded database ),
non avete un IP statico? ma dinamico, lanciare il comando "ip a"
prendere
il valore di inet: nella sezione della scheda di rete (per esempio 192.168.1.108).
Correggere in: impostazioni di rete, modalità ipv4, con manuale, indirizzo
uguale 192.168.1.108 e gateway 192.168.1.1, aggiungere al dns il valore del gateway,
con utente di root correggere i valori in "/etc/netplan/"
il più recente ...yaml come:
network:
version: 2
ethernets:
NM-dfghjk9-8927-6754-22d3-0g78907q6613:
renderer: NetworkManager
match:
name: "enp2s0"
dhcp4: true
# addresses:
# - "192.168.1.108/24"
nameservers:
addresses:
- 1.1.1.1
- 1.0.0.1
- 192.168.1.1
dhcp6: true
(eccetera ...)
Attenzione: i caratteri (#) contano, sono la chiave di volta, permettono a
Oracle-xe-21c di vedere IP statico ed il sistema operativo di funzionare in Dhcp,
fare un riavvio (del servizio) e voilà.
da rpm a deb: sudo alien -c -d --fixperms oracle-database-xe-21c.rpm
installare: sudo dpkg -i ./oracle-database-xe-21c.beb
completare la user oracle: cambiare il terminale in "/etc/passwd"
in bash, creare il folder di default "/home/oracle" cambiare
"chwon -R oracle:dba /home/oracle" copiare da un altro utente
".profile" e completarla con:
if [ -d "/opt/oracle/product/21c/dbhomeXE" ] ; then
PATH="$PATH:/opt/oracle/product/21c/dbhomeXE"
export PATH
fi
if [ -d "/opt/oracle/product/21c/dbhomeXE/bin" ] ; then
PATH="$PATH:/opt/oracle/product/21c/dbhomeXE/bin"
export PATH
fi
export ORACLE_HOME=/opt/oracle/product/21c/dbhomeXE
export ORACLE_BASE=/opt/oracle/product/21c/dbhomeXE
ORACLE_SID="XE"
export ORACLE_SID
accedere e completare ".bashrc" con:
cd
if [ -d "/opt/oracle/product/21c/dbhomeXE/bin" ] ; then
PATH="$PATH:/opt/oracle/product/21c/dbhomeXE/bin"
export PATH
fi
. oraenv1
dove oraenv1 clone di oraenv con eliminata la selezione del SID, imposto fisso
"XE", controlliamo i gruppi della user con:
"cat /etc/passwd |grep /home |grep -v false |cut -d: -f1 |xargs groups
|grep oracle"
otteniamo la lista (oinstall dba oper backupdba dgdba kmdba
racdba) se tutto sistemato e provato possiamo installare il DB.
configurazione: da root "/etc/init.d/oracle-xe-21c configure"
controlli finali: eseguire da brouser "https://localhost:5500/em/"
con user: system e (pw) quella impostata durante il passo di install, provare:
"sudo -S /etc/init.d/oracle-xe-21c start"
"sudo -S /etc/init.d/oracle-xe-21c stop "
"sudo -S /etc/init.d/oracle-xe-21c status"
da una procedura per esempio in rexx:
"push (pw)"
"sudo -S -i -u oracle lsnrctl status"
ed il listener/sql da utente oracle:
"lsnrctl stop"
"lsnrctl start"
"lsnrctl status"
"sqlplus / as sysdba"
"show pdbs;"
"select * from v$version;"
"select instance_name, status, database_status from v$instance;"
da un gestore per esempio DBeaver impostando i dati (host: 192.168.1.108 port: 1539
db: XE, SID, "Oracle Database Native", user: sys, pw: (pw), role: sysdba).
Con il comando:
sudo xhost +si:localuser:oracle
sistemiamo il display, vedi dbca, xclock, xeyes, ultimo neo da sistemare il
clipboard manager,
|
|
| |
Install PostgreSql su Client Linux (Ubuntu ram 32G)
Usato in modalità integrato nei programmi ( embedded database ),
spettacolare la semplicità di primo approdo, tutto si svolve con fluidità
e semplicità. Parlando di un prodotto che supporta più database il
primo ostacolo è dovuta alla normalizzazione delle include sql, le built-in
fanno il loro lavoro, peccato per i cursori, la declare deve essere spostata vicino
alla open, comporta un supplemento di controlli.
Le operazioni sql risentono dei linguaggi nativi risultano notevolmente più
criptiche rispetto all'approccio dei precedenti database.
Un ulteriore difficoltà è la completa incomprensione della messaggistica,
le anomalie del precompilatore sono "mitiche" non esistono riferimenti ne al
Database ne al sorgente, stessa sorte per il compilatore. Sicuramente il suo utilizzo
è orientato verso linguaggi che non sanno gestire le chiavi tradizionali e si
appoggiano alle chiavi surrogate, con la tecnica: se raddoppi semplifichi!? O meglio
non capisco ma ho scritto.
Il database è orientato verso un utilizzo esclusivo come Open Database Connectivity
(ODBC).
|
|
| |
Esempi di Cobol con Apache2 e Db2
( un click sulla descrizione per attivare il Link al Video )
Debug realizzato con il solo Cobol
Alcune pagine, le più vintage (qualche ritocco alla fine
dello scorso secolo):
Debug versione 2008 con interfaccia The-editor (Hessing):
|
|
|
![]() stop/start images
stop/start images
|
|